A Segregeringsmål
Et kendt og ofte anvendt citat, der definerer segregering, er fra Massey og Dentons (1988) klassiske artikel, hvor de skriver: “At a general level, residential segregation is the degree to which two or more groups live separately from one another, in different parts of the urban environment” (s. 282). Citatet indfanger den centrale logik, når vi taler om segregering. Segregering er en situation, hvor folk i en given kontekst—være det uddannelsessystemer(t), arbejdsmarkedet eller boligmarkedet—ikke møder hinanden eller er eksponerede for hinanden. Det vil sige, at under absolut segregering går folk fra forskellige baggrunde ikke på de samme skoler, arbejder ikke på de samme arbejdspladser og bor ikke i de samme nabolag.
Segregeringslitteraturen har en lang metodologisk tradition (Fossett, 2017; James & Taeuber, 1985; Reardon & Firebaugh, 2002). Nogle mål for segregering er dog mere fremtrædende end andre i den empiriske litteratur. Mål for ulige fordeling og eksponering/isolering er generelt de mest anvendte. Det er også disse mål, der har mest substantiel relevans i studiet af (minoritets)gruppers fordeling mellem skoler, arbejdspladser og nabolag. Dette bilag beskriver og diskuterer to mål for segregering: et, der måler fordeling (dissimilaritetsindekset), og et, der måler eksponering eller isolation (separationsindekset).
Eftersom nærværende bilag er en bred introduktion til disse to mål for segregering og ikke er specifik til en enkelt analyse fra bogen anvendes to generaliserede termer i det følgende: Enheder, som referer til en given geografisk ”position”—det kan være en skole, en arbejdsplads eller et nabolag—og områder, der referer til et givent ”sted”, der indeholder de pågældende enheder, såsom et kommunalt/nationalt skolelandskab, arbejdsmarked eller boligmarked.
A.1 Dissimilaritetsindekset
I forskningslitteraturen er det mest anvendte mål for segregering dissimilaritetsindekset (\(D\)), der blev bredt introduceret af Duncan & Duncan (1955). Selvom \(D\) oprindeligt blev udviklet til at beskrive boligsegregering, har indekset også siden i vidt omfang været anvendt til at beskrive skolesegregering og segregerings på arbejdsmarkedet samt andre former for fordeling af personer og grupper.
Med James & Taeuber (1985) notationer er \(D\) udregnet som:
\[\begin{equation} \tag{A.1} D=\frac{ {\textstyle \sum_{i=1}^{k} \left | p_{i} - P \right | } }{ 2TP \left ( 1-P \right ) } \end{equation}\]
\(D\) er et to-gruppe mål, hvilket vil sige, at det kun kan sammenligne graden af segregering—eller fordeling—af to grupper. Det vil sige at hvis en population er udgjort af flere grupper, kan målet kun bestemme den parvise segregering. Populationen i udregningen består derfor af to gensidigt udelukkende grupper \(g \in (A, B)\). Disse grupper kan være numeriske minoriteter/majoriteter eller enhver anden meningsfuld gruppering, såsom etniske klassifikationer, så længe de er gensidigt udelukkende. Majoriteten betegnes her som \(A\) og minoriteten som \(B\), og den absolutte størrelse af henholdsvis gruppe \(A\) og \(B\) er udtrykt som \(N^{A}\) og \(N^{B}\), mens \(T=\left( N^{A} + N^{B} \right)\) er den samlede population i et område på tværs af enheder. Individuelle enheder, såsom skoler, arbejdspladser eller nabolag, refereres til som \(i \in (1, 2, \dots, k)\). Den totale populationsstørrelse i de individuelle enheder betegnes som \(n_{i}^{*}\). Andelen af personer i majoritetsgruppen i den individuelle enhed, \(p_{i}\), er givet som \(p_{i} = \frac{n_{i}^{A}}{n_{i}^{A} + n_{i}^{B}}\), mens \(P = \frac{N^{A}}{N^{A} + N^{B}}\) udtrykker den samlede andel af personer i majoritetsgruppen i hele området.
I ligning (A.1) udtrykker tælleren summen af den absolutte afvigelse af hver enkelt enheds majoritetsandel fra den samlede andel i populationen i området \(\left( \left| p_{i} - P \right| \right)\). Herfra bestemmes \(D\) endeligt ved at dividere med nævneren, som er den maksimalt mulige \(D\)-score, der er lig \(2TP \left( 1-P \right)\) (se Zoloth, 1976). Dette skalerer indekset til en score mellem 0 og 1 og udtrykker afvigelsen fra “lige fordeling” som en brøkdel af den maksimalt mulige ulige fordeling.
\(D\) kan mest simpelt tolkes som den andel af elever fra én af grupperne, der skal flyttes til en ny enhed, mens der sendes samme andel fra den anden gruppe til afsenderenheden, for at \(p_{i}\) er lige for alle enheder i et givent område. Med andre ord måler \(D\) rent teknisk fordeling (eng.: “displacement”) udtrykt som fordelingen af personer i de to grupper mellem enheder, der er henholdsvis over eller under paritet (lige fordeling).
Med skolesegregering som eksempel, vil det sige, hvor mange børn fra gruppe \(A\) går i skoler, hvor enten \(p_{i}>P\) eller \(p_{i}<P\), og vice versa for børn i gruppe \(B\). Mere konkret udtrykt, i en given kommune, måles, hvor mange børn med majoritetsbaggrund går i en skole, hvor andelen af majoritetsbørn er enten højere eller lavere end andelen af majoritetsbørn i hele kommunen. Ulige fordeling er høj, når en stor andel af majoritetsbørnene går i skoler, hvor andelen af majoritetsbørn er højere end den samlede andel i kommunen (\(p_{i} > P\)), og en tilsvarende andel af minoritetsbørn går i skoler, hvor andelen af majoritetsbørn er lavere end den kommunale andel (\(p_{i} < P\)). Målet bygger på en binær opdeling af over/under paritet, således at personer i et område, hvor \(p_{i}>P\), scores 1, og personer, hvor \(p_{i}<P\), scores 0. Det er disse aggregerede værdier, der opsummeres til en skaleret værdi i ligning (A.1). I tilfælde af perfekt fordeling mellem enheder, hvor \(D\) = 0, gælder det, at \(p_{i}=P\) for hver enkelt enhed. For eksempel i en kommune, hvor 10% af alle børn har en minoritetsbaggrund, skal hver skole have en andel af minoritetsbørn på 10% (\(p_{i}\) = 0.1) for at \(D\) = 0, uafhængigt af skolernes størrelse.33 Værdier over 0 frem mod maksimum, 1, udtrykker hvor stor en andel af en af grupperne, som befinder sig i enheder over eller under paritet.
Det er en central pointe, at \(D\) måler, hvor ulige to grupper er fordelt mellem enheder, uafhængigt af gruppernes størrelse. Det er kun andelen af hver gruppe i hver enhed, der er af betydning for målet. Målet er derfor sammensætningsinvariant (eng.: ”composition invariant”). Hvilket vil sige, at målet ikke er påvirket af ændringer i de absolutte størrelser af grupperne, der sammenlignes. Det betyder, at selv hvis de relative størrelser af grupperne ændres i den samlede population (\(P\)), men fordelingen mellem enheder (\(p_{i}\)) er uændret, forbliver \(D\)-indekset uændret. Dermed opfylder indekset den egenskab, at \(D \left( \alpha A, \beta B \right) = D \left( A, B \right)\): Hvis størrelsen på den samlede gruppe, \(A\) eller \(B\), bliver skaleret op eller ned med skaleringsfaktorer \(\alpha\) og \(\beta\), vil indekset forblive det samme, så længe fordelingen af grupperne relativt til hinanden forbliver den samme. For eksempel, hvis en årgang af skolebørn består af to grupper og andelen af gruppe \(B\) stiger (mens andelen af \(A\) falder), vil \(D\) forblive uændret, hvis den relative andel af gruppe \(A\) og \(B\) på hver enkelt skole forbliver den samme. Denne egenskab gør det muligt at sammenligne graden af segregering mellem områder eller over tid, selv hvis den demografiske populationssammensætning er forskellig eller ændrer sig. Grundet denne egenskab bliver \(D\) ofte fremhævet som et robust mål for sammenligning af segregering mellem forskellige kontekster.
Sammensætningsinvariansen betyder dog ikke, at de relative andele, grupperne udgør i et område, er uden betydning for den overordnede forventede grad af segregering i det pågældende område. Særligt hvis minoritetsgruppen er markant mindre end majoritetsgruppen, og antallet af enheder sætter en strukturel betingelse for mulige fordelinger af de to grupper (se kapitel 4 for et empirisk eksempel). I figur A.1 vises simuleringer af 1.000 tilfældige fordelinger (iid) af en gruppe på 100 personer inddelt i 2 grupper mellem 10 enheder og fordelingen af de 1.000 målte \(D\)-scores for otte forskellige relative gruppeandele. Som vi ser, kan segregering variere relativt meget for en given befolkningssammensætning som resultatet af rene tilfældigheder, men spændet af forventede minimums- og maksimumsværdier er strukturelt betinget af de relative andele, som grupperne udgør, når der er et fast antal enheder, som populationen kan fordeles mellem.
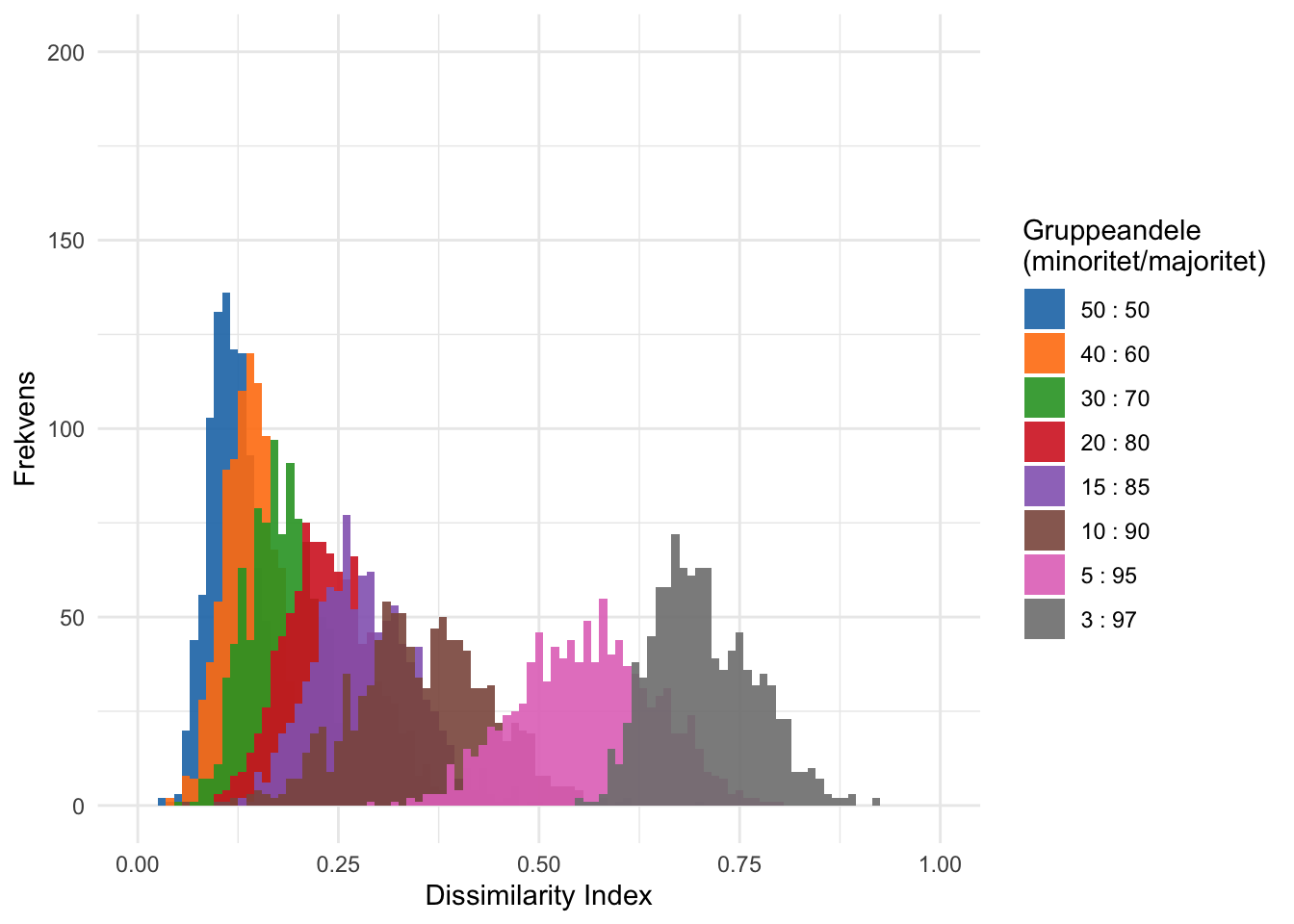
Figur A.1: Simuleret fordeling af D index under forskellige relative gruppestørrelser i population på 100 personer
Dette leder til en central pointe, der ofte overses i anvendelsen af \(D\). Populationssammensætningsinvarians og indeksets fokus på relativ fordeling mellem enheder gør indekset meget følsomt over for størrelsen og antallet af enheder. Denne egenskab kan gøre sammenligninger mellem forskellige kontekster problematiske. Hvis det fysiske skolelandskab (antallet og størrelsen af skoler) varierer markant mellem to kommuner, vil forskellen i observeret \(D\) også udtrykke denne strukturelle forskel i skolelandskabet mellem kommunerne. Dette er et velkendt problem i den geografiske litteratur, kendt som “the Modifiable Areal Unit Problem” (MAUP). Relateret hertil er også det klassiske problem i geografiske analyser kendt som “the small-unit bias,” hvor det mange steder er vist, at tilfældig fordeling mellem små enheder systematisk kan resultere i høj segregering (Carrington & Troske, 1997).
Opsummeret betyder det, at selvom \(D\)-indekset principielt kan variere fra 0 til 1 (ingen \(\rightarrow\) komplet segregering), vil “ingen segregering” være tæt på umulig at opnå, hvis grupperne varierer markant i størrelse, som vi også ser i figur A.1. Der kan simpelthen være for få minoriteter og for mange enheder til, at deres fordeling mellem enheder kan matche majoritetens fordeling (Harris, 2017). Som diskuteret i kapitel 4 er dette forhold aktuelt i den danske case, hvor andelen af minoriteter, selvom den er stigende, har været og fortsæt er relativt lille i mange kommuner.
A.2 Korrigeret D-indeks
En måde at tilgå begrænsningen, at tilfældige fordelinger også kan producere relativt høje grader af segregering, er blevet præsenteret af Harris (2017). Blandt Harris’ metodiske bidrag til segregeringslitteraturen er en udvidelse af \(D\)-indekset, der korrigerer målet for det gennemsnitlige niveau af segregering under forudsætning af tilfældig fordeling (iid), givet de faktiske gruppestørrelser og enheder. Dette gennemsnit er afledt af simulerede fordelinger af en population mellem enheder, efter samme logik som figur A.1. Denne korrigering af \(D\) tager altså højde for, at selvom segregering måles til at være høj, kunne denne grad af segregering være opstået under tilfældig fordeling af grupperne under de givne strukturelle forhold. Diop & Larsen (2024) anvender denne korrigering af den målte segregering for at kunne bidrage med en mere nuanceret beskrivelse af segregering på det danske arbejdsmarked i en kontekst med ændrende demografiske forhold over tid, se kapitel 5.
A.3 Separationsindekset
Hvor sammensætningsinvariansen ofte fremhæves som en attraktiv egenskab ved \(D\), er det dog også en tilbagevendende diskussion i den metodiske litteratur, at det ikke i alle situationer er en attraktiv egenskab ved et segregeringsmål. Særligt ikke hvis vi eksplicit er interesserede i sociale interaktioner mellem grupper. Sammensætningsinvariansen gør nemlig, at \(D\) per definition ikke opfanger ændringer i strukturelle betingelser for intergruppe eksponering på individuelt niveau. Ulige fordeling mellem enheder betyder nemlig ikke nødvendigvis separering mellem grupper. Med separering menes der fysisk adskillelse af grupperne i hverdagen og ikke blot om en person befinder sig i en enhed, hvor der er højere eller lavere andel af personer fra samme gruppe, relativt til det større område, da det kan indbefatte områder, som fortsat er relativt befolkningsmæssigt heterogene.
For at kunne svare på, om grupperne ikke bare er ulige fordelt mellem enheder, men faktisk separeret i deres daglige liv—det vil sige, at de ikke forventes at mødes tilfældigt en given dag—kræver det en beskrivelse af, om den ulige fordeling er koncentreret i få enheder eller spredt over flere enheder. Er ulige fordeling koncentreret, betyder det, at de to grupper befinder sig i enheder (skoler, nabolag, arbejdspladser, etc.), som er homogene. Det vil sige, at enten minoriteten eller majoriteten udgør hele eller størstedelen af populationen i hver enhed. Er ulige fordeling modsat spredt, betyder det, at minoritetsgruppen er tyndt spredt mellem enkelte af enhederne i området. Dette betyder, at gruppen er ulige fordelt, fordi populationen ikke er lige repræsenteret i alle enheder, men samtidig varierer befolkningssammensætningen kun moderat mellem enheder. Dette er ofte tilfældet, hvis minoriteten er markant mindre end majoriteten.
Implikationen er, at hvis ulige fordeling er spredt, vil der stadig være relativt høj gensidig eksponering mellem minoritets- og majoritetsgruppen i forhold til, hvor meget eksponering der strukturelt er muligt. I modsætning til ulige fordeling, der er koncentreret, hvor hver gruppe primært er eksponeret for deres egen gruppe. Det vil sige, at grupperne er isolerede og primært kun er eksponeret til personer fra deres egen gruppe. I det første tilfælde er grupperne altså ikke separerede da grupperne stadig er eksponerede for hinanden i det omfang, det kan lade sig gøre under de strukturelle forudsætninger givet ved populationssammensætningen og antallet og størrelsen af enheder. Med andre ord er den typiske enhed i et område befolkningsmæssigt homogen. \(D\) kan ikke beskrive denne separation, idet ulige fordeling ikke per definition signalerer disproportional koncentration af grupper—hvilket til tider er en forfejlet opfattelse i segregeringsstudier (Fossett, 2017).
Separering kan i stedet beskrives med Separationsindekset34 (\(S\)), som måler forskellen i den parvise majoritets-minoritets eksponering til majoritetsgruppen. Det vil sige, at \(S\) måler den vægtede forskel mellem gruppe \(A\)’s eksponering til gruppe \(A\) (ind-gruppe isolation) og gruppe \(B\)’s eksponering til gruppe \(A\) (ud-gruppe eksponering). \(S\) er ligesom \(D\) et to-gruppe mål for segregering, som måler den relative grad af segregering mellem to grupper. Men hvor \(D\) udtrykker fordeling, udtrykker \(S\) sandsynlighed for eksponering mellem to grupper.
Med de samme notationer som i foregående sektion kan \(S\) udregnes35 som:
\[\begin{equation} \tag{A.2} S = \frac{{\textstyle \sum_{i=1}^{k}} n_{i}^{*} \left ( p_{i}-P \right )^{2} }{ TP \left ( 1-P \right ) } \end{equation}\]
Ligesom dissimilaritetsindekset anvender separationsindekset også \(P\) som grundlag for sammenligning mellem enheder, men bestemmer afvigelsen af hver enkelt enheds gruppesammensætning (\(p_{i}\)) fra \(P\) med andre regler. Hvor \(D\) måler den absolutte afstand mellem \(p_{i}\) og \(P\), er \(S\) givet som den kvadrerede forskel mellem \(p_{i}\) og \(P\) vægtet i forhold til størrelsen af de enkelte enheder, \(n_{i}^{*}\). Målet er endeligt afledt ved at dividere med den maksimalt mulige score i nævneren for at standardisere målet til en 0–1 skala (James & Taeuber, 1985; Zoloth, 1976). Med andre ord måler vi andelen af den samlede varians i en afhængig variabel, der kan forklares ved forskelle mellem grupper.
Selvom ligning (A.2) på mange måder ligner ligning (A.1) har forskellen i bestemmelsen af de summerede afvigelser fra “lige fordeling” stor substantiel betydning for, hvad indekset faktisk måler, og tolkningen af segregering. \(S\) repræsenterer ikke (u)lige fordelinger, men forskellen i parvis skaleret eksponering. \(S\) måler derfor sandsynligheder for intergruppeeksponering, korrigeret for den samlede populationssammensætning (Bell, 1954; Fossett, 2017) udtrykt som en brøkdel af den maksimalt mulige eksponering.
Vægtningen af indekset relaterer sig til, at \(S\) er afledt af isolerings- og eksponeringsindeksene (\(P^{*}\)-indeks, se Farley, 1984), som udtrykker sandsynligheden for, at to tilfældigt udvalgte personer i en enhed tilhører samme eller forskellige grupper (Gorard & Taylor, 2002).36
Problemet ved at anvende \(P^{*}\) ukorrigeret i bestemmelsen af den relative isolation af grupperne, er, at den mindste værdi \(P^{*}\) kan tage, er den heterogene blanding af gruppe \(A\) i et pågældende område, givet som \(N^{A}/N^{B}\) (se Bell, 1954). Derfor gælder det også, at sandsynligheden for intragruppeeksponering i gruppe \(A\) er større end i gruppe \(B\), hvis gruppe \(A\) udgør en større andel af populationen, selv hvis populationen er ligeligt fordelt mellem enheder. Hvis der ikke korrigeres for populationsstørrelser (\(T=N^{A}+N^{B}\)), kan komparative beskrivelser af forventet eksponering, givet alene som \(P^{*}\), mellem områder derfor være delvist vildledende i en substantiel tolkning.
Hvis vi forestiller os to kommuner: den ene kommune (\(X\)) består af 30% personer fra gruppe \(B\), mens den anden kommune (\(Y\)) består af 2% personer fra gruppe \(B\). Selv hvis minoritetsgruppen var ligeligt fordelt mellem alle enheder i hver kommune, således at alle enheder har den samme andel—altså ingen segregering målt som \(D\)—vil det i kommune \(X\) gælde, at \(P^{*}\) = 0.3, mens det i kommune \(Y\) gælder at \(P^{*}\) =0.02. Med disse “rå” mål for eksponering er høje/lave grader af eksponering ikke nødvendigvis et udtryk for segregering, men kan blot reflektere, at der er flere personer fra gruppe \(B\) i den ene kommune sammenlignet med den anden. Med andre ord, med \(D\) ser vi ingen forskelle i segregeringsniveau mellem \(X\) og \(Y\), selvom der tydeligvis er substantielle forskelle i graden af intergruppeeksponering, mens vi med \(P^{*}\) kan ende med en beskrivelse, der grundlæggende ikke siger andet end “der er flere minoriteter i \(X\) end i \(Y\)”. En forskel, der ikke nødvendigvis udtrykker en forskel i segregeringsprocesser mellem kommunerne, kun potentialet for omfanget af segregering.
\(S\) imødegår disse begrænsninger. Forskellen på \(P^{*}\) og \(S\) er, at \(S\) er en normalisering af \(P^{*}\)-målene, der kontrollerer for befolkningssammensætningen og samtidig eliminerer asymmetrien i målene. Ved at normalisere med hensyn til størrelsen på enhederne (\(n_{i}^{*}\)) og den maksimalt mulige eksponering/isolering (\(TP(P-1)\)) udledes et mål, hvor den ekstreme minimumsværdi 0 repræsenterer en situation, hvor den sandsynlige eksponering mellem grupperne er lig den hypotetiske sandsynlige eksponering, hvis gruppe \(A\) var lige fordelt mellem enheder. Den ekstreme maksimumsværdi 1 opnås i situationer, hvor sandsynligheden for tilfældig eksponering mellem to personer fra hhv. gruppe \(A\) og gruppe \(B\) i en given enhed er 100%. \(S\) er altså udtrykt som en brøkdel af den maksimalt mulige intergruppeeksponering.
Denne korrigering for befolkningssammensætning har den implikation, at segregeringsmålets forventede spænd mellem minimum og maksimum ikke på samme måde er følsomt overfor relative gruppestørrelser (se figur A.2). \(S\) forventede spænd er dog strukturelt påvirket af antallet af enheder, som en population kan blive sorteret mellem (se figur A.3). Som Fossett (2017) har demonstreret, indeholder \(S\), i kombination med mål for fordeling som \(D\), dermed information om, hvorvidt ulige fordeling er koncentreret eller spredt. Hvis \(S\) er lavt, mens \(D\) er højt, vil den ulige fordeling være karakteriseret som spredt, mens et højt \(S\) og højt \(D\) indikerer en koncentreret og ulige fordeling. Som Fossett skriver, \(S\) tjener derfor som en indikation på ‘prototypisk segregation,’ hvilket repræsenterer en faktisk adskillelse mellem grupper snarere end blot en ujævn fordeling af en minoritetsgruppe” (Fossett, 2017, s. 96, egen oversættelse).
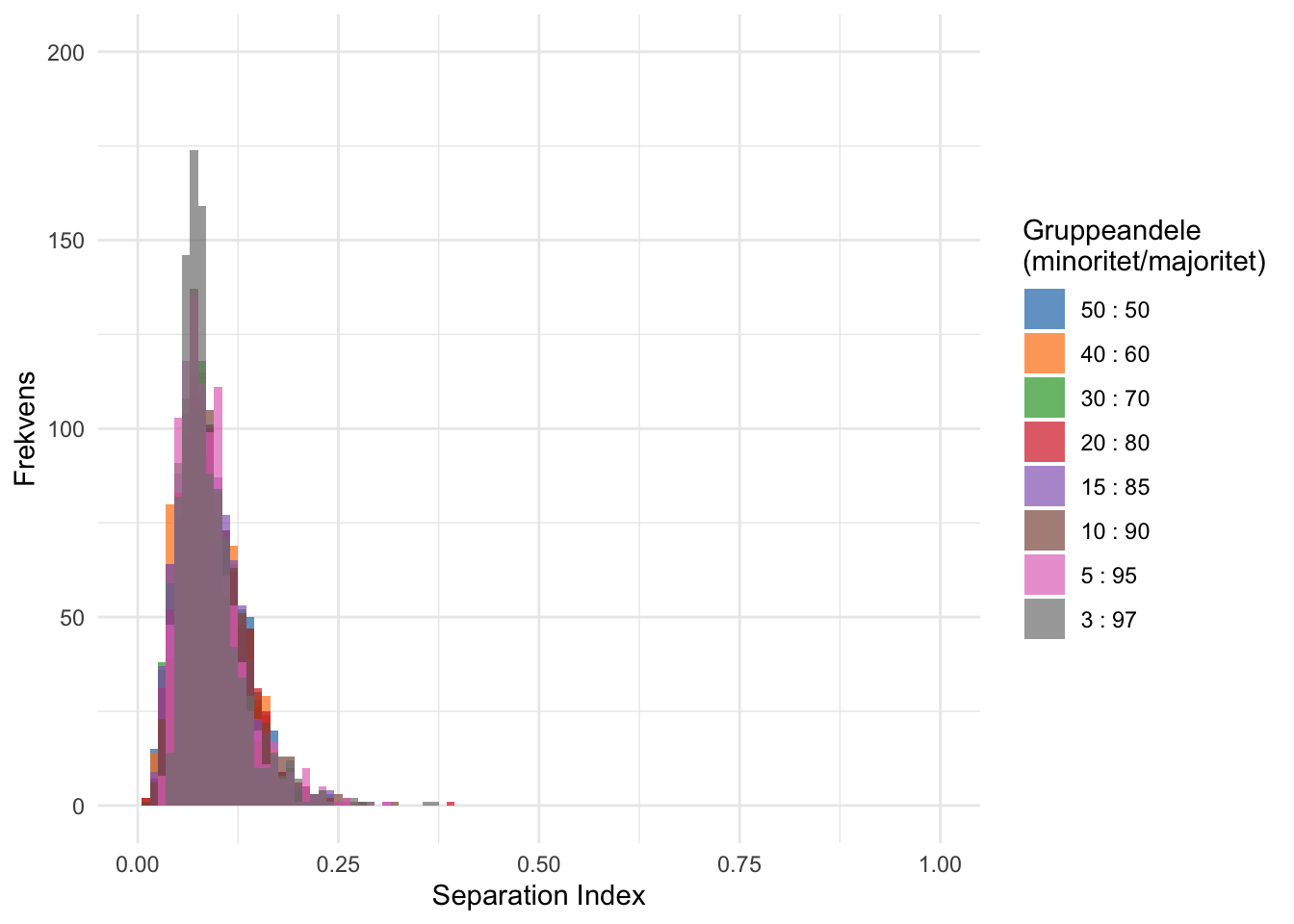
Figur A.2: Simuleret fordeling af S index under forskellige relative gruppestørrelser i population på 100 personer (10 enheder).
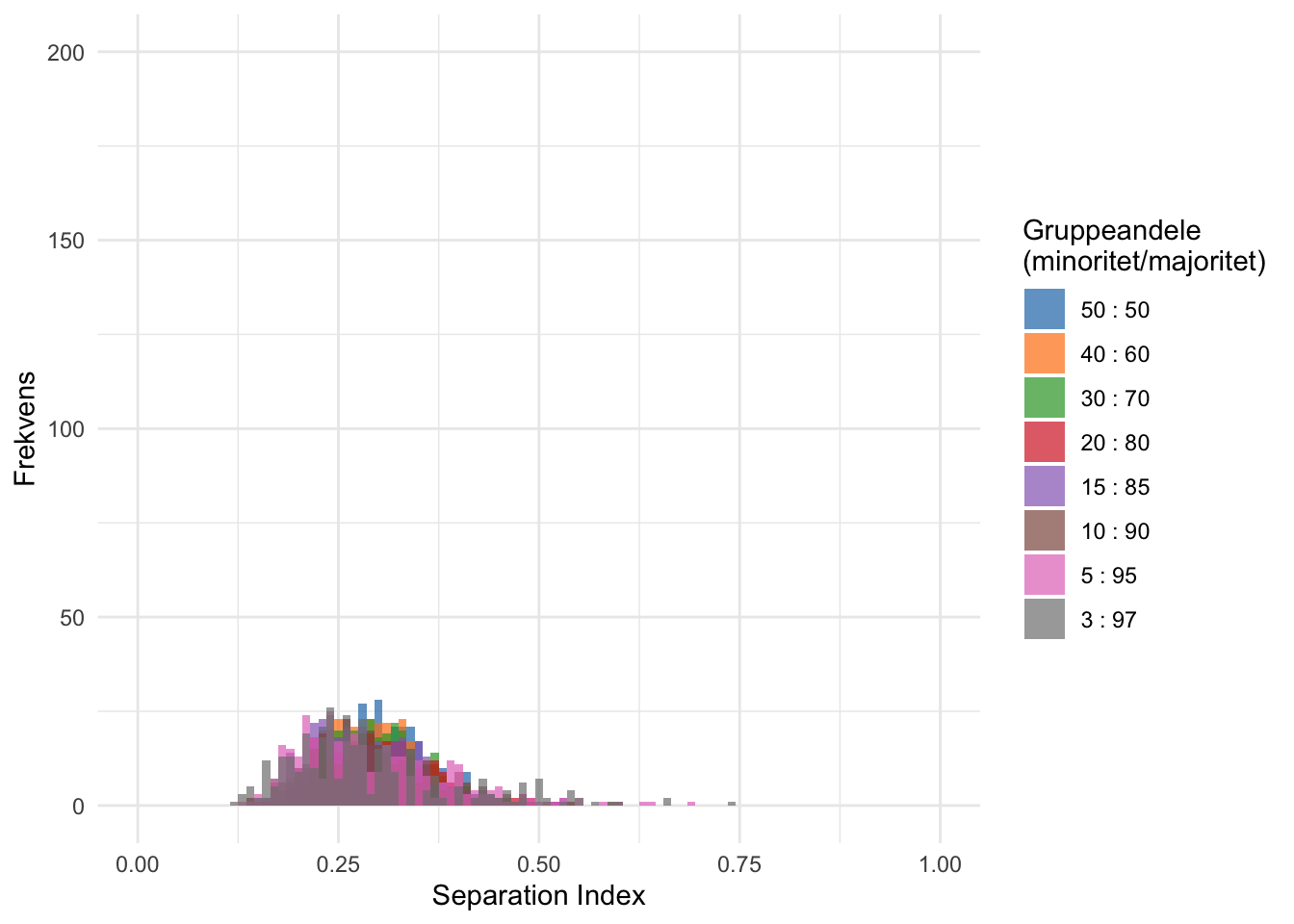
Figur A.3: Simuleret fordeling af S index under forskellige relative gruppestørrelser i population på 100 personer (30 enheder).
A.4 Sammenhæng mellem S og D
I praksis ser vi ofte, at \(S\) og \(D\) korrelerer, men graden af korrelation kan variere betydeligt mellem områder, fordi \(D\) ikke per definition signalerer polarisering og koncentreret fordeling mellem grupper. \(S\) og \(D\) kan have samme score, men kun i tilfælde, hvor begge mål er \(1\), hvilket udtrykker en situation, hvor begge grupper befinder sig i homogene enheder, hvor de udgør 100% af populationen. Altså, når koncentrationen mellem enheder i et område er ved deres maksimum vil \(S=D\). Når \(S\) og \(D\) er identiske eller tilnærmelsesvis af samme størrelsesorden er segregering derfor karakteriseret som det, Fossett (2017) kalder “prototypisk segregering.” Når \(S\) og \(D\) derimod divergerer med en høj \(D\)-score men lav \(S\)-score, er fordelingen af majoriteter og minoriteter mellem enheder karakteriseret som en “ulige men spredt fordeling”. Det vil sige, at selvom minoritetsgruppen ikke er repræsenteret i alle enheder i et givent område, udgør de fortsat en numerisk minoritet i de enheder, hvor de er repræsenteret, se [kapitel 4](#kap4] for eksempel. Minoritetsgruppen er simpelthen for lille—eller for “tyndt spredt”—til at kunne udgøre numerisk overtal i nogen af enhederne i et område. I absolutte værdier kan \(S\) derfor heller ikke være større end \(D\). Derfor er tommelfingerreglen, at når grupper varierer meget i relative størrelser og/eller antallet af enheder er højt, kan \(S\) strukturelt være nævneværdigt lavere end \(D\) (se figur A.2 og figur A.3). Se figur A.4 for stiliserede beskrivelser af de tre mulige idealtypiske kombinationer af \(S\) og \(D\).

Figur A.4: Mulige kombinationer af (absolutte) S-D værdier efter Fossett (2017, s. 85).
Note: Bemærk dog hertil at denne kvadrat ikke er identistisk til signaturforklaringen i figur 4.3 og figur 4.4, hvor der eksisterer en top-venstre kvadrant, hvad der i figur A.4 ville være nedre-højre kvadranten, som illustrerer at både D og S er relativt lave værdier; ikke at de har samme absolutte værdi.
Konceptuelt ligner \(D\) derfor den klassiske Gini Koefficient (\(G\)) og Lorenz kurven, idet \(D\) udtrykker den gennemsnitlige afvigelse af majoritetsandelen for hver skole (\(p_{i}\)) fra populationsandelen af majoritetsgruppen (\(P\)), udtrykt som en brøkdel af den maksimalt mulige afvigelse. Det vil sige, at \(D\)-indekset rent teknisk måler den maksimale vertikale afstand mellem Lorenz-kurven og ”line of equity” (perfekt lige fordeling) (Allen & Vignoles, 2007; Frankel & Volij, 2011). \(G\) måler på den anden side arealet mellem disse to linjer.↩︎
Et problem gennem segregeringslitteraturen er, at Separationsindekset er kendt under mange navne (Fossett, 2017), da metodiske artikler ofte har valgt at give indekset et nyt navn, som de finder mere korrekt. Indekset er derfor også kendt som The revised index of isolation, The correlation ratio eller \(eta^{2}\), \(r_{ij}\), The variance ratio og The segregation index.↩︎
Da ligning (A.2) i denne kontekst estimerer forskelle i gennemsnittene for hver gruppe, er \(S\) her estimeret som determinationskoefficienten \(R^2\) fra en lineær regression, hvor den afhængige variabel (andel af minoritetsgruppen) regresseres på en gruppeindikator, \(g\). Regressionen vægtes med enhedsstørrelserne, \(n_{i}^{*}\), for at sikre, at større enheder bidrager proportionalt mere til den samlede forklarede varians, som udtrykt i ligning (A.2). \(R^2\) i sådanne en lineær model udtrykker dermed andelen af variation i udfaldet, som kan tilskrives gruppering og svarer derfor til en simpel og ligefrem udregning af ligning (A.2).↩︎
Eksponeringsindekset, \(_{A}P^{*}_{B}\), udtrykker sandsynligheden for, at en tilfældig person fra \(A\) befinder sig i en enhed med en person fra \(B\). Isoleringsindekset, \(_{A}P^{*}_{A}\), udtrykker derimod sandsynligheden for, at en tilfældig person fra \(A\) befinder sig i en enhed med en anden fra \(A\). To meget forsimplede antagelser er dog nødvendige i denne tolkning (Bell, 1954). For det første antages det, at møder mellem personer foregår inden for den pågældende enhed (skoler, arbejdspladser, nabolag), og for det andet, at hver person i en pågældende enhed har lige sandsynlighed for at møde hver enkelt person inden for enheden. Det er veldokumenteret, at begge antagelser ikke er tilfældet i praksis (McPherson et al., 2001). \(P^{*}\) skal derfor tolkes som den minimale sandsynlige eksponering mellem personer fra samme/forskellige grupper, under antagelse af at den faktiske intragruppe eksponering er højere. Begge mål—isolering og eksponering—kan tage værdier fra 0 til 1, og hvis populationen er inddelt i kun to grupper, gælder det, at \(_{A}P^{*}_{B} + _{A}P^{*}_{A} = 1\). Derudover er målene asymmetriske, hvilket betyder, at \(_{A}P^{*}_{B} = _{B}P^{*}_{A}\) kun i tilfælde, hvor \(A\) og \(B\) udgør lige store andele af befolkningssammensætningen, eller \(_{A}P^{*}_{B} \neq _{B}P^{*}_{A}\). Disse mål opfylder derfor ikke sammensætningsinvariansen, men er afhængige af størrelsen på de grupper, der sammenlignes (Massey & Denton, 1988), da sandsynligheden for eksponering eller isolering er summen af produktet af to sandsynligheder (se Bell (1954)): (1) sandsynligheden for, at en person fra gruppe \(A\) møder en anden person fra gruppe \(A\): \(\left( n_{i}^{A} - 1 \right) / \left( n_{i}^{B} - 1 \right)\), og (2) sandsynligheden for, at en tilfældig person fra gruppe \(A\) befinder sig i den pågældende enhed, \(i\): \(n_{i}^{A} / N^{A}\). Et produkt, der kan udtrykkes algebraisk som: \(P^{*}=\frac{1}{A} {\textstyle \sum_{i=1}^{k}\frac{n_{i}^{A \space 2}}{n_{i}^{B}}}\). Sandsynligheden for intergruppeeksponering—eller relativ isolation—tager altså afsæt i befolkningssammensætningen.↩︎